Why it exists
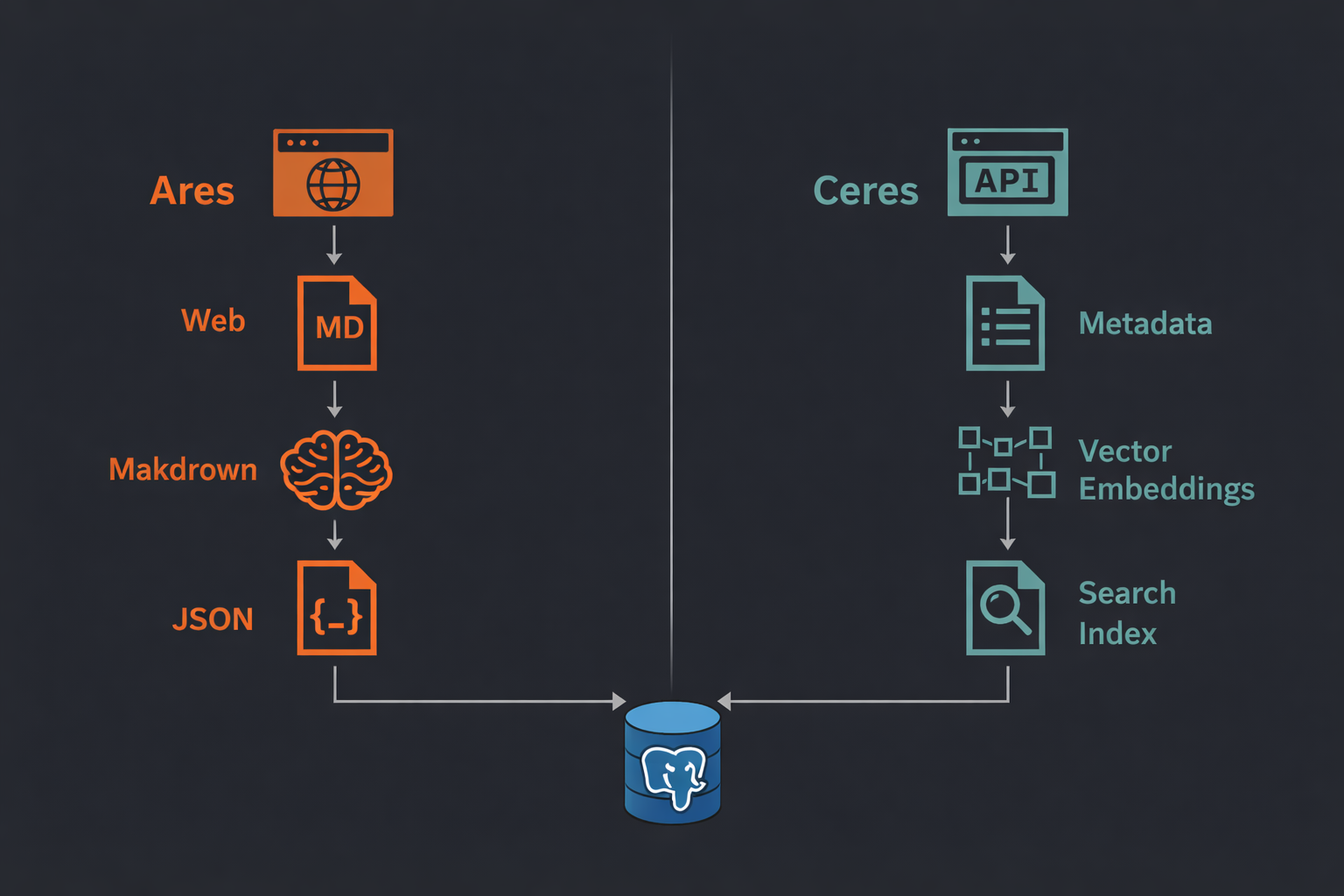
Harvesting and scraping are different operational contracts, and treating them as the same thing usually makes both systems worse. Ceres is about respectful, repeatable synchronization from known open-data portals, while Ares is about extracting structure from less predictable web pages where fetch behavior, schema drift, and retries have to be explicit parts of the system.
Technical center
Ceres centers on incremental portal sync and catalog durability, while Ares focuses on fetch pipelines, markdown normalization, JSON Schema extraction, retries, and queue-driven execution. Splitting the tools keeps the architecture honest: one side optimizes for catalog freshness and exportability, the other for controlled extraction runs that can survive partial failures and changing page structure.
Current proof points
The distinction is already concrete in the READMEs: Ceres offers incremental portal sync, metadata-only mode, export, and optional semantic search, while Ares offers schema-driven extraction, change detection, queue workers, crawl sessions, and protected API endpoints for scrape orchestration. Together they describe a collection stack where ingestion is not just about getting bytes, but about preserving the operational promise behind each source.