Perché esiste
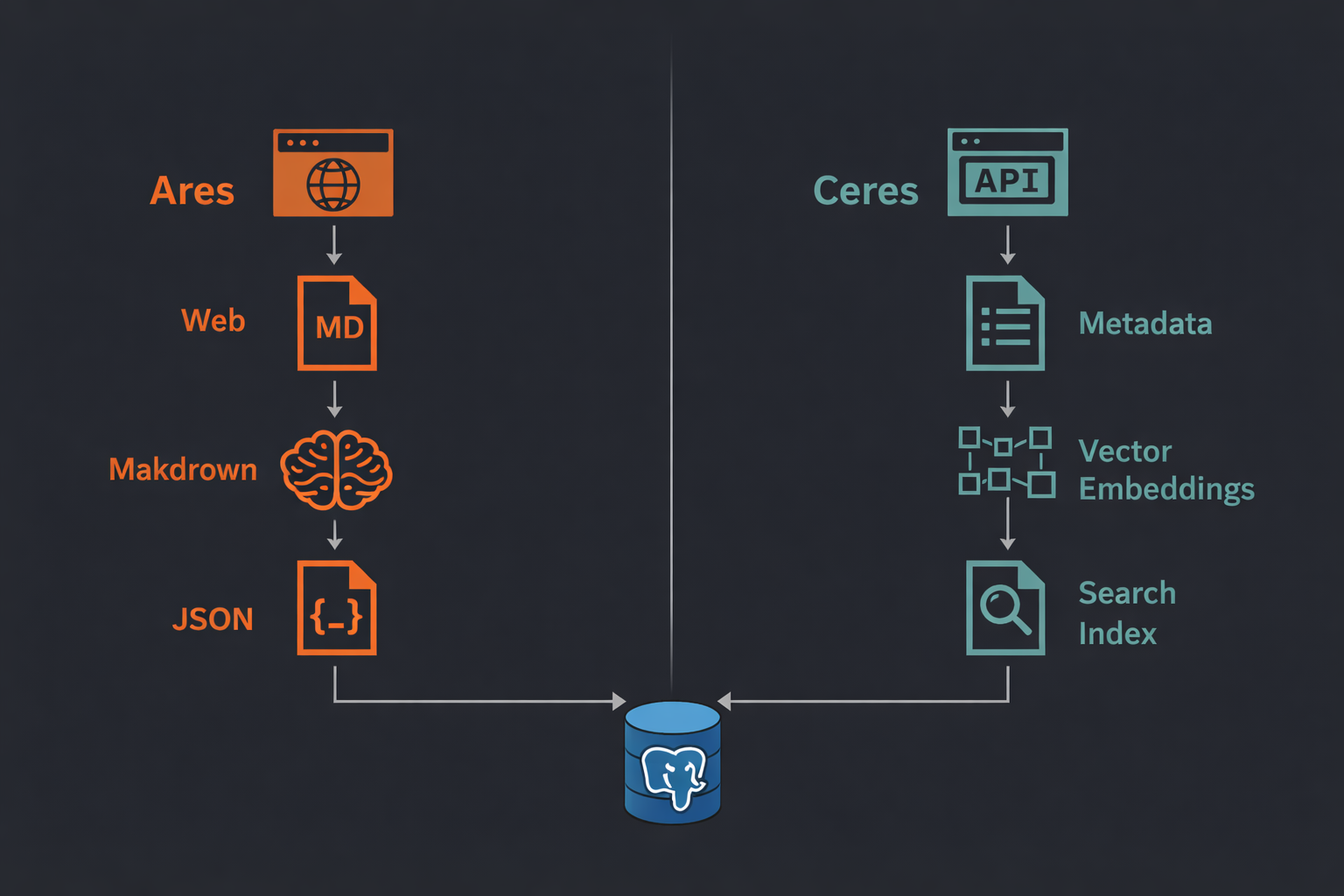
Harvesting e scraping sono contratti operativi diversi, e trattarli come se fossero la stessa cosa di solito peggiora entrambi i sistemi. Ceres riguarda la sincronizzazione rispettosa e ripetibile da portali open-data noti, mentre Ares riguarda l'estrazione di struttura da pagine web meno prevedibili, dove comportamento di fetch, drift di schema e retry devono essere parti esplicite del sistema.
Centro tecnico
Ceres si concentra sulla sincronizzazione incrementale dei portali e sulla durabilità del catalogo, mentre Ares si focalizza su pipeline di fetch, normalizzazione markdown, estrazione JSON Schema, retry ed esecuzione guidata da code. Separare i due tool mantiene onesta l'architettura: un lato ottimizza per freschezza ed esportabilità del catalogo, l'altro per run di estrazione controllati che sopravvivono a fallimenti parziali e a strutture di pagina che cambiano.
Prove correnti
La distinzione è già concreta nei README: Ceres offre sincronizzazione incrementale dei portali, modalità metadata-only, export e ricerca semantica opzionale, mentre Ares offre estrazione guidata da schema, change detection, queue worker, sessioni di crawl ed endpoint API protetti per orchestrare lo scraping. Insieme descrivono uno stack di raccolta in cui l'ingestion non è solo prendere byte, ma preservare la promessa operativa dietro ogni sorgente.