Why it exists
Profiling should be something a team can run inside CI, scheduled data checks, or batch workflows, not a one-off notebook ritual that falls apart on wide tables or larger files. dataprof exists to make the first question about a dataset cheap and repeatable: what shape is it, where are the suspicious columns, and what can be checked again the next time the file or table changes?
Technical center
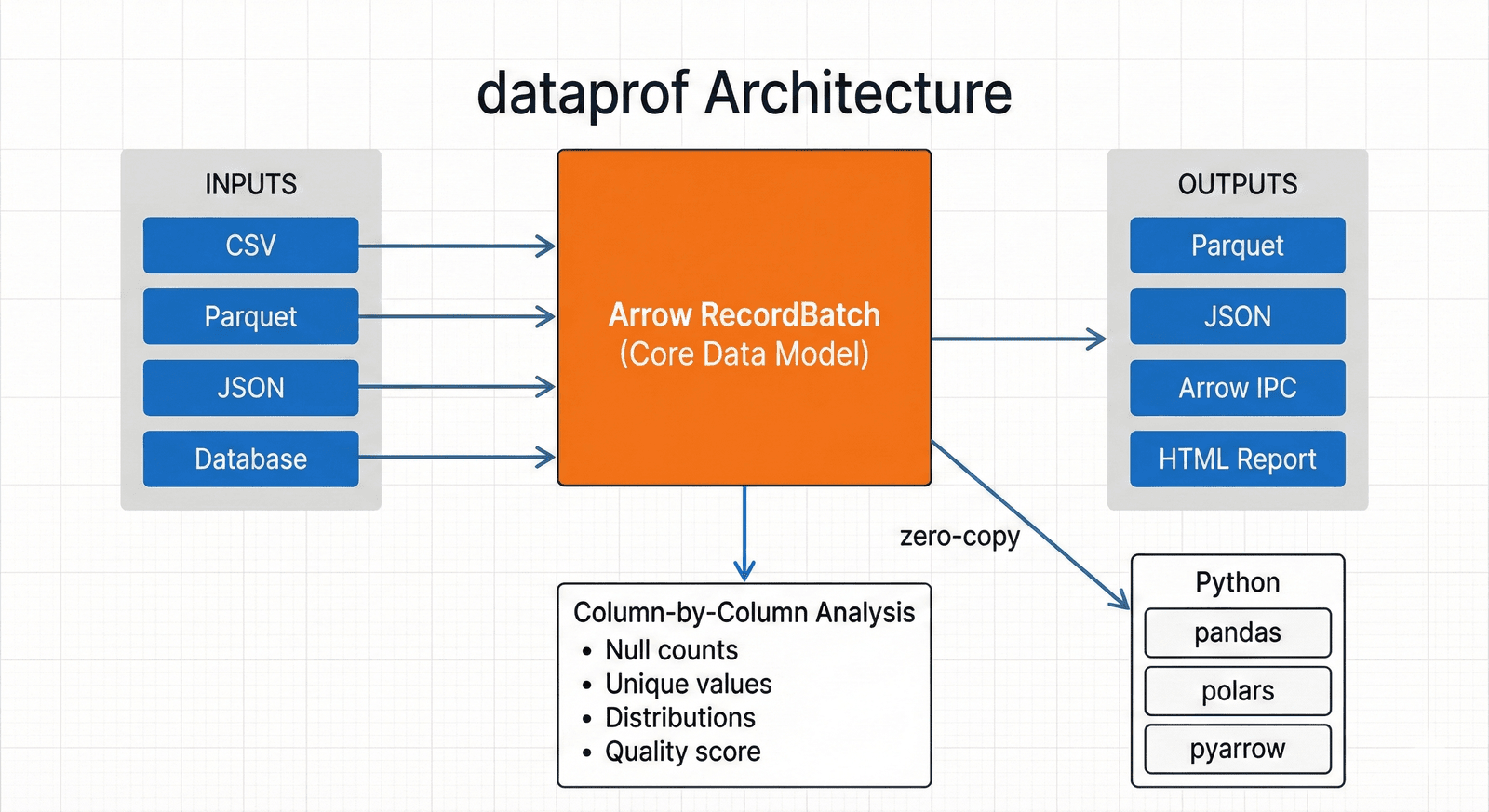
dataprof treats Arrow arrays and RecordBatches as the core abstraction, so column metrics, type and pattern detection, Parquet and IPC interoperability, and the future SQL layer via DataFusion all line up around the same in-memory model. That choice keeps the Rust core close to modern analytical storage while still leaving clean interfaces for a CLI, a Python package, and machine-readable reports that can be consumed by other tools.
Current proof points
The public surface already shows the real shape of the project: a Rust crate, CLI, and PyPI package, selective metrics for cheaper runs, bounded-memory execution, and an Arrow-centered design story that led to two upstream arrow-rs Parquet documentation PRs rather than a private workaround. The important part is not only that it profiles data, but that the project is being pushed toward the same operational places where data quality checks actually need to live.