Perché esiste
La profilazione dovrebbe essere qualcosa che un team può eseguire dentro la CI, in controlli pianificati o in workflow batch, non un rituale da notebook che crolla su tabelle larghe o file più grandi. dataprof esiste per rendere la prima domanda su un dataset economica e ripetibile: che forma ha, dove sono le colonne sospette e cosa si può verificare di nuovo la prossima volta che il file o la tabella cambia?
Centro tecnico
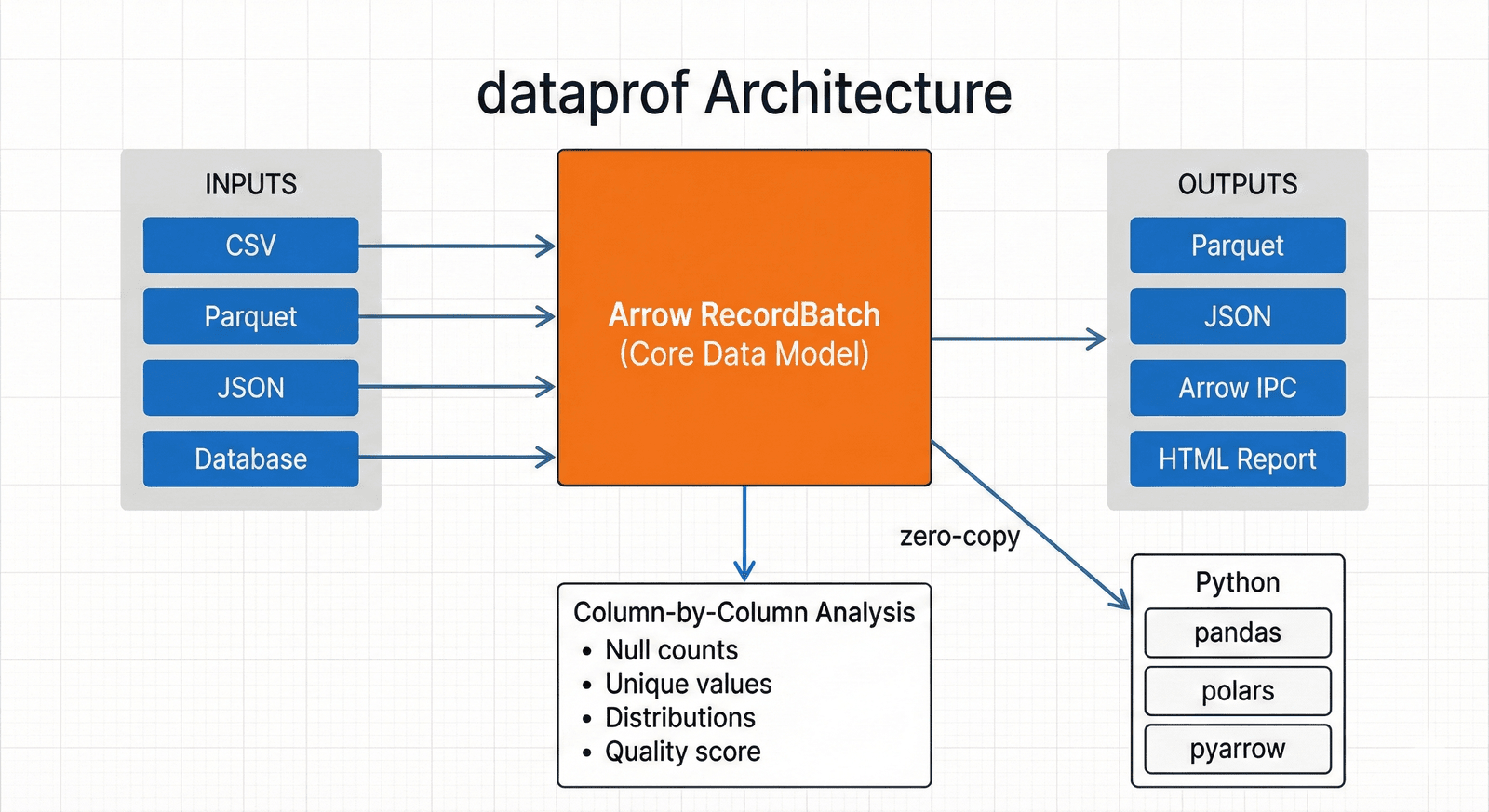
dataprof tratta gli array Arrow e i RecordBatch come astrazione di base, così metriche per colonna, riconoscimento di tipi e pattern, interoperabilità Parquet e IPC e il futuro layer SQL via DataFusion si allineano tutti sullo stesso modello in memoria. Questa scelta tiene il core Rust vicino allo storage analitico moderno lasciando però interfacce pulite per una CLI, un pacchetto Python e report machine-readable consumabili da altri strumenti.
Prove correnti
La superficie pubblica mostra già la forma reale del progetto: un crate Rust, una CLI e un pacchetto PyPI, metriche selettive per run più economici, esecuzione a memoria limitata e una storia di design centrata su Arrow che ha portato a due PR di documentazione upstream su arrow-rs per Parquet invece di un workaround privato. La parte importante non è solo che profila dati, ma che il progetto viene spinto verso gli stessi luoghi operativi in cui i controlli di qualità dei dati devono effettivamente vivere.