Introduzione
Continuando il viaggio nell’ecosistema Rust del data engineering iniziato con l’articolo su RisingWave, voglio esplorare un progetto a cui ho recentemente contribuito: Lakekeeper, il catalogo REST per Apache Iceberg completamente scritto in Rust.
Ho scoperto Lakekeeper mentre cercavo soluzioni per costruire un lakehouse completamente Rust-native. Dopo aver studiato il codebase e contribuito al progetto, ho capito che rappresenta un tassello fondamentale per completare la visione di un lakehouse moderno, sicuro e performante.
Dal Precedente Articolo: Il Pezzo Mancante
Nell’articolo su RisingWave avevamo visto come l’implementazione Rust di Apache Iceberg fosse nata da una collaborazione tra RisingWave e Xuanwo, con la donazione del progetto icelake alla Apache Foundation. Avevamo discusso delle lacune dell’ecosistema Rust-Iceberg e di come RisingWave stesse colmando il gap per costruire streaming lakehouse moderni.
Ma c’era un componente cruciale ancora mancante: il catalogo. Senza un catalogo sicuro, performante e aperto, l’intera visione di un lakehouse Rust-native rimaneva incompleta. Lakekeeper nasce proprio per colmare questo vuoto.
Il Problema che Lakekeeper Risolve
I cataloghi esistenti presentano limitazioni significative. Unity Catalog, inizialmente sviluppato per Delta Lake in Databricks, si sta aprendo alla comunità ma rimane focalizzato sull’ecosistema Databricks. Apache Polaris, contribuito da Snowflake, è vendor-neutral ma richiede una JVM. Entrambi, pur essendo soluzioni valide, non offrono la combinazione di apertura, customizzabilità, supporto on-premise e footprint ridotto che molte organizzazioni cercano.
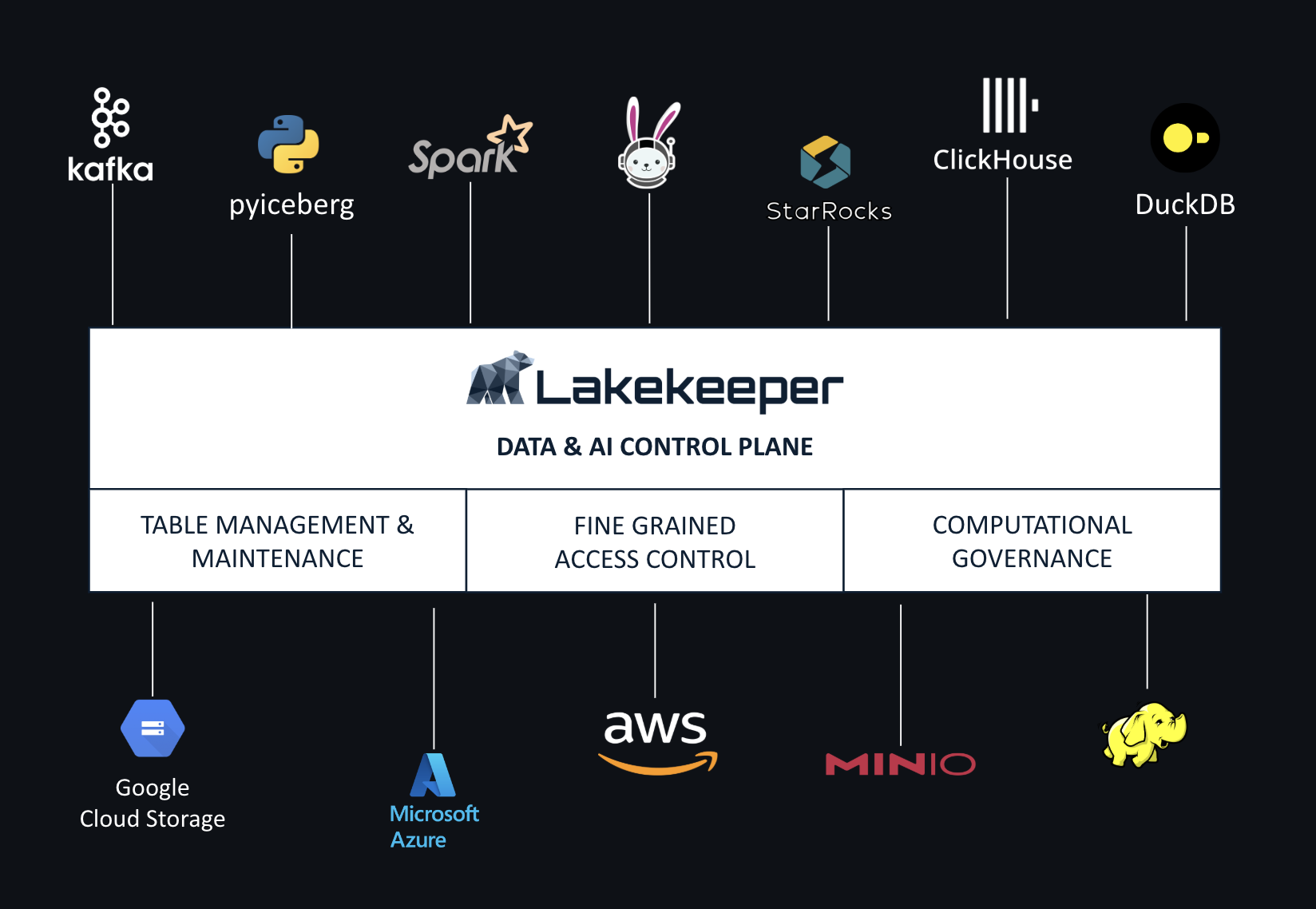
Il catalogo è essenzialmente il “bibliotecario” del data lakehouse: tiene traccia di quali tabelle esistono, dove si trovano e quale versione dei metadati è corrente. Senza un catalogo, i sistemi di storage come S3 rimangono semplicemente un insieme di file senza governance. Il catalogo trasforma lo storage ordinario in un lakehouse completamente governato, supportando transazioni ACID, time travel e viste consistenti tra tutti i motori di query.
Perché Rust? Vantaggi Architetturali Concreti
Lakekeeper è implementato interamente in Rust, una scelta che porta vantaggi misurabili:
Deployment semplificato: Singolo binario di 30-70 MB senza dipendenze da JVM o runtime Python. Deployabile persino in container distroless senza shell, riducendo drasticamente la superficie di attacco e i requisiti di memoria.
Performance elevate: Grazie al modello di ownership di Rust e all’assenza di garbage collection, Lakekeeper raggiunge latenze ridotte per operazioni di metadati e gestione credenziali. Questo si traduce in query più veloci e costi operativi inferiori.
Memory safety: Le garanzie del compilatore Rust eliminano intere classi di bug (use-after-free, data races) che affliggono sistemi scritti in C/C++ o che richiedono attenzione manuale in Go.
Customizzabilità: L’architettura modulare espone trait Rust per componenti chiave: Catalog, SecretsStore, Authorizer, CloudEventBackend, ContractVerification. In pratica, potete integrare Lakekeeper in qualsiasi stack aziendale implementando poche interfacce.
Architettura e Componenti Principali
Lakekeeper si articola su tre crate principali: iceberg-catalog contiene la logica core, iceberg-catalog-bin fornisce l’entry point dell’applicazione, mentre iceberg-ext estende le funzionalità di iceberg-rust. Questa struttura modulare riflette il design pattern Rust di componenti riutilizzabili e facilmente testabili.
Il sistema segue un approccio stateless a livello applicativo. Lo stato viene persistito in un database PostgreSQL versione 15 o superiore, permettendo scalabilità orizzontale semplicemente aggiungendo istanze.
Per deployment production, Lakekeeper supporta connessioni separate per letture e scritture. Questo permette di distribuire le query di read su repliche PostgreSQL dedicate, migliorando le performance complessive senza modificare l’applicazione.
Due cache in-memory accelerano operazioni critiche. La STC Cache memorizza credenziali cloud temporanee con un limite default di 10,000 entries. La Warehouse Cache riduce query al database per warehouse lookup, con default 1,000 entries. Entrambe espongono metriche Prometheus per monitoraggio granulare: dimensione cache, hit totali e miss totali.
Sicurezza: Vended Credentials e Authorization
Quello che mi ha colpito di più di Lakekeeper è la Storage Access Management attraverso vended credentials e remote signing. Invece di memorizzare credenziali a lungo termine nei client, il catalogo emette credenziali temporanee con scope limitato a specifiche tabelle. In pratica, questo significa implementare il principio di least-privilege access just-in-time, allineandosi ai moderni principi di sicurezza zero-trust.
Il processo funziona così: quando un query engine deve accedere a una tabella, si autentica con Lakekeeper usando credenziali di servizio. Il catalogo verifica che il principal sia autorizzato per quella tabella e restituisce i metadati insieme a credenziali temporanee per la location di storage. Queste possono essere AWS STS token, Azure SAS token o GCP OAuth 2.0.
Le credenziali hanno breve scadenza e permessi minimi, garantendo accesso solo ai file di quella specifica tabella. Non più credenziali hardcoded con accesso permanente a interi bucket S3.
Per l’autenticazione, Lakekeeper si integra nativamente con Identity Provider via OpenID Connect e supporta Kubernetes Service Accounts. La configurazione è semplice: basta specificare l’URI del provider OpenID e il catalogo verifica automaticamente gli access token.
Per l’autorizzazione, il sistema utilizza OpenFGA, un progetto CNCF che implementa un modello di permessi con ereditarietà bi-direzionale. Questo gestisce lakehouse moderni con namespace gerarchici, supportando grant granulari a livello di server, project, warehouse, namespace, table e view.
La versione 0.6.0 ha introdotto il bridge OPA che espone i permessi gestiti da Lakekeeper a motori di query esterni come Trino. I compute engine possono così applicare automaticamente le policy di accesso a livello di tabella, colonna e row senza duplicare la logica di autorizzazione.
Change Events e Governance Event-Driven
Lakekeeper supporta nativamente Change Events basati su CloudEvents, lo standard CNCF per descrivere eventi in modo uniforme. Il catalogo riceve informazioni su qualsiasi cambiamento alle tabelle attraverso gli endpoint REST chiamati dai client. Lakekeeper trasforma questi table updates in CloudEvents, permettendo di reagire a modifiche in tempo reale.
Gli eventi possono essere emessi verso backend configurabili come NATS o Kafka. Questo abilita pattern interessanti: trigger automatico di data quality pipelines quando nuovi dati vengono inseriti, invalidazione di cache downstream quando i metadati cambiano, tracking completo di modifiche per compliance, o integrazione con sistemi di approval per change management.
Il sistema supporta anche Change Approval tramite il trait ContractVerification. Modifiche possono essere bloccate da sistemi esterni, permettendo ad esempio di prevenire cambiamenti che violerebbero Data Contract o SLO di qualità definiti esternamente.
Multi-Tenancy e Deployment Production
Lakekeeper segue un approccio multi-tenant: un singolo deployment può servire multipli progetti, ognuno con più warehouse a cui i compute engine possono connettersi. Tutti i tenant condividono la stessa infrastruttura ma i dati sono partizionati logicamente tramite identificatori.
Ogni progetto supporta warehouse multipli, permettendo di segregare ambienti come production, staging e development, o team diversi mantenendo un unico punto di gestione centralizzato. Il modello di database normalizzato introdotto nella versione 0.5 memorizza TableMetadata attraverso tabelle multiple invece di un singolo binary blob, rendendo gli aggiornamenti più veloci.
Per deployment in produzione, la checklist include database Postgres ad alta disponibilità, configurazione di connessioni separate per read/write, deployment di istanze multiple tramite Helm chart ufficiale, autenticazione via OpenID Connect, e configurazione di metriche Prometheus con alert per cache hit rate, latenze ed errori.
L’Integrazione con RisingWave: Stack Rust-Native Completo
Il collegamento con RisingWave, discusso nell’articolo precedente, è particolarmente rilevante. RisingWave ha introdotto il supporto per cataloghi REST Iceberg nella versione 2.5, con integrazione nativa per Lakekeeper come catalogo di default per scenari self-hosted.
L’esempio pratico è semplice: con docker-compose-with-lakekeeper.yml si avvia un cluster RisingWave e il catalogo REST Lakekeeper. Si crea una connessione in RisingWave che punta a Lakekeeper (catalog.type = 'rest', catalog.uri = 'http://lakekeeper:8181/catalog/'), si imposta come default, e qualsiasi dato streamato nella tabella viene automaticamente committato in formato Iceberg su object storage (MinIO, S3, Azure Blob).
Dal lato query, DuckDB, Spark, Trino o Starburst possono attaccarsi allo stesso catalogo REST Lakekeeper e interrogare le tabelle create da RisingWave. Questo dimostra l’interoperabilità multi-engine: RisingWave scrive dati real-time, Lakekeeper gestisce i metadati e la governance, altri engine leggono i dati per analytics batch.
RisingWave ha anche integrato un compaction engine basato su DataFusion, il query execution framework Rust che usa Apache Arrow come formato in-memory. DataFusion viene utilizzato come fondazione per numerosi progetti (InfluxDB, ParadeDB, GreptimeDB, Arroyo) ed è particolarmente adatto per compaction Iceberg grazie alla sua performance e integrazione con l’ecosistema Arrow.
Questo stack RisingWave + Lakekeeper + DataFusion rappresenta un’architettura completamente Rust-native per streaming lakehouse: ingestione real-time, compaction efficiente, catalogo sicuro, tutto senza JVM. È il paradigm shift da architetture JVM-dominant (Kafka → Spark → Data Warehouse) a architetture polyglot Rust-accelerated (RisingWave → Iceberg → Lakekeeper → Data Lakehouse).
Lakekeeper nel Panorama dei Cataloghi 2025
Nel panorama dei cataloghi Iceberg, Lakekeeper si distingue per caratteristiche specifiche:
Apache Polaris (incubating), sviluppato da Snowflake e contribuito ad Apache, è un catalogo fully-featured vendor-neutral che implementa la REST API standard Iceberg. Polaris può essere eseguito come servizio centralizzato o hosted nel cloud Snowflake, supportando engines diversi.
Databricks Unity Catalog è una soluzione proprietaria di governance unificata per data e AI assets nel lakehouse Databricks. Mentre Unity supporta Iceberg, è ottimizzato principalmente per Delta Lake.
Lakekeeper si posiziona come alternativa con:
- Lightweight footprint: Singolo binario 30-70MB vs JVM-based solutions
- Sicurezza built-in: Vended credentials, OpenFGA, OIDC integration nativa
- Completa apertura: Apache License senza vendor lock-in
- Focus on-premise e hybrid: Oltre al cloud, supporto robusto per deployment self-hosted
Adoption e Ecosystem
Lakekeeper è già utilizzato in diversi contesti. Compare nella lista “Users” del repository apache/iceberg-rust insieme a Databend, RisingWave e Wrappers. Viene integrato da piattaforme managed come Starburst, ClickHouse e Crunchy Data Warehouse.
Il progetto ha rilasciato la versione 0.1.0-rc1 a giugno 2024 e da allora segue una cadenza mensile. La versione 0.6.0 ha introdotto l’OPA bridge per Trino e supporto per Iceberg 1.5-1.7. La 0.7.0 ha aggiunto Azure Managed Identities e CloudEvents per undropTabulars. La 0.8.1 ha introdotto protezioni per tabelle, view, namespace e warehouse.
Il Mio Contributo al Progetto
Ho iniziato a seguire Lakekeeper attratto dalla promessa di un catalogo Iceberg scritto in Rust che risolvesse i problemi di apertura e customizzabilità. Dopo aver studiato il codebase, ho identificato un’area dove potevo contribuire e ho aperto una pull request che è stata mergiata.
L’esperienza di contribuire è stata positiva: il processo di review è rapido e costruttivo, tutte le commit passano attraverso PR con CI checks rigorosi (lints, integration tests con Spark, PyIceberg, Trino, StarRocks). Il progetto ha test di integrazione estensivi che garantiscono compatibilità multi-engine.
Il progetto richiede attualmente il CLA (Contributor License Agreement) firmato su GitHub, ma stanno pianificando di donare Lakekeeper a una foundation - probabilmente Apache, Linux Foundation o una Lakekeeper Foundation dedicata - durante il 2026.
Perché Lakekeeper Ha Bisogno di Contributors
Lakekeeper è un progetto promettente che beneficerebbe enormemente da più contributor. Alcune aree dove la community può contribuire:
Feature development: Il supporto per HDFS come Storage Profile non è ancora completo. L’ecosistema di Views in Iceberg è in evoluzione e richiede ulteriori integration test.
Documentazione: Sebbene la documentazione ufficiale su docs.lakekeeper.io sia migliorata significativamente, ci sono sempre casi d’uso avanzati da documentare.
Integration testing: Più coverage per compute engine diversi (Flink, Presto, altri) aiuterebbe la stabilità.
Kubernetes Operator: Attualmente work-in-progress, rappresenta una priorità per semplificare deployment enterprise.
Se siete interessati all’intersezione tra Rust e data engineering, Lakekeeper rappresenta un’eccellente opportunità per contribuire a un progetto con impatto reale sull’ecosistema open lakehouse.
Roadmap e Visione Futura
La roadmap futura include estensioni del concetto di catalogo oltre Iceberg: gestione di AI objects, volumes metadata per training model su PDFs e immagini. Il catalogo può evolvere per fornire access control per AI assets tramite metadata di volumi, espandendo la governance lakehouse all’intero stack dati-AI.
Il Kubernetes Operator semplificherà deployment enterprise gestendo Lakekeeper come Custom Resource. L’integrazione con ulteriori Identity Provider e authorization systems è in discussione per supportare diversi stack aziendali.
Conclusione: Completare il Puzzle Rust-Data
Lakekeeper, nel contesto dell’articolo precedente su RisingWave, completa il quadro di un’architettura streaming lakehouse Rust-native credibile. Non è solo un catalogo Iceberg alternativo: è un esempio di come governance, sicurezza e performance possano coesistere in un sistema aperto e customizzabile.
L’ecosistema Rust nel data engineering è ancora giovane ma in rapida crescita. L’integrazione di Rust nel Linux kernel (2024) e l’adozione da parte di cloud provider (AWS Firecracker) segnalano crescente accettazione in infrastrutture critiche. Lakekeeper si posiziona in questa transizione: abbastanza maturo per production, abbastanza agile per innovare rapidamente.
Per organizzazioni che costruiscono lakehouse moderni, Lakekeeper offre una via verso full ownership dei metadati, libertà da vendor lock-in, e governance enterprise-grade mantenendo l’apertura dell’ecosistema open data. La scelta Rust non è solo tecnica ma strategica: posiziona Lakekeeper nel cuore dell’evoluzione verso stack data cloud-native, performanti e sicuri.
Se siete interessati a contribuire, il progetto è su GitHub con documentazione completa, quick-start guide e una roadmap chiara. L’ecosistema ha bisogno di più persone che credano negli standard aperti e nella collaborazione reale sui dati.