
Un signore ha fotografato il link
Il 3 giugno ero al Talent Garden di Rende, sul palco, con il talk trasmesso anche in streaming su StreamYard grazie agli amici di Azure Meetup Puglia che lo hanno gestito. In sala una cinquantina, sessantina di persone. Ho fatto una demo di Brain UI dal vivo su un dataset mock a tema Pokémon, la tassonomia più sgargiante che ho, quella in cui il grafo prende davvero vita.
A un certo punto la mia ragazza, che guardava dalle sedie, ha notato un signore tra il pubblico fotografare il dominio mostrato a schermo. Rimarrà un po’ deluso: non può ancora usarlo in quel modo. Quel piccolo momento mi ha fatto sorridere, e mi è rimasto impresso, perché racchiudeva la cosa che tutta la sala sembrava condividere quella sera. Non la curiosità per un grafo di Pokémon, ma un interesse comune e reale per una domanda: che aspetto ha davvero una knowledge base aziendale quando la vuoi fruibile sia dagli umani sia dagli agenti, non solo dagli uni o dagli altri.
Questo articolo è l’approfondimento per cui non ho avuto tempo sul palco. Cosa sono Brain e Brain UI, come si collegano le due metà, una tassonomia reale config-driven da un dominio che sto studiando, e le ragioni oneste per cui sto per rendere open source il core.
Due metà: Brain e Brain UI
Il sistema è diviso in due di proposito.
Brain è il contenuto. È una semplice cartella di file Markdown versionata in Git. Note atomiche, decisioni, verbali di riunione, runbook, work item, preventivi. Nessun database detiene la verità, nessun formato proprietario fa lock-in. Se Brain UI sparisse domani, Brain resterebbe un repository Git pulito di Markdown che puoi leggere in qualsiasi editor, grepare da terminale, o passare a qualunque altro strumento. Il punto è esattamente questo.
Brain UI è il control plane. È un’applicazione Rust costruita su Leptos 0.8, server-side rendered con hydration WASM, con Axum 0.8 sotto per il server HTTP, le sessioni e l’auth. Legge il Markdown da un repository GitHub, lo renderizza, ti permette di modificare e creare documenti che vengono riscritti tramite le API di GitHub, e visualizza le relazioni tra le note come un grafo interattivo.
Il legame tra le due è la parte a cui tengo di più: Git resta la single source of truth, sempre. Brain UI non diventa mai il posto dove la tua conoscenza vive di nascosto. Ogni scrittura torna su GitHub come un commit reale, con un diff reale, che avresti potuto fare a mano. Brain UI è una lente e un editor sopra il tuo repository, non un silo che possiede i tuoi dati.
Perché l’ho costruito
L’origine onesta è poco glamour: documentazione sparsa e frammentata in troppi posti. Brain è il tentativo di raccoglierla in un punto comune, facile da esportare, con piena proprietà del dato. Testo semplice in Git significa che non c’è nessun vendor tra me e la mia stessa conoscenza.
Mentre lo costruivo, Andrej Karpathy ha pubblicato il suo gist llm-wiki, e descriveva, quasi riga per riga, la forma verso cui stavo già convergendo. Una knowledge base personale fatta di Markdown semplice che un agente costruisce e mantiene attivamente: le sorgenti grezze restano immutabili, uno strato wiki è di proprietà dell’LLM, e un file di schema (lui lo chiama CLAUDE.md o AGENTS.md) tiene le convenzioni. Tre operazioni: ingest, query, lint. Il lint in particolare cerca contraddizioni e pagine orfane senza link entranti.
Brain è arrivato nello stesso territorio dalla direzione opposta. Il file di schema esiste, si chiama .brain-config.yml. Brain stesso ha un AGENTS.md. Brain UI già segnala i nodi orfani con un banner informativo e risolve i riferimenti incrociati come archi del grafo. La differenza è che volevo una vera interfaccia sopra la cartella, qualcosa che un non-programmatore possa aprire e navigare, non solo un coding agent puntato su una directory. Una knowledge base davvero fruibile, per umani e agenti allo stesso tempo, era l’obiettivo fin dall’inizio.
L’architettura
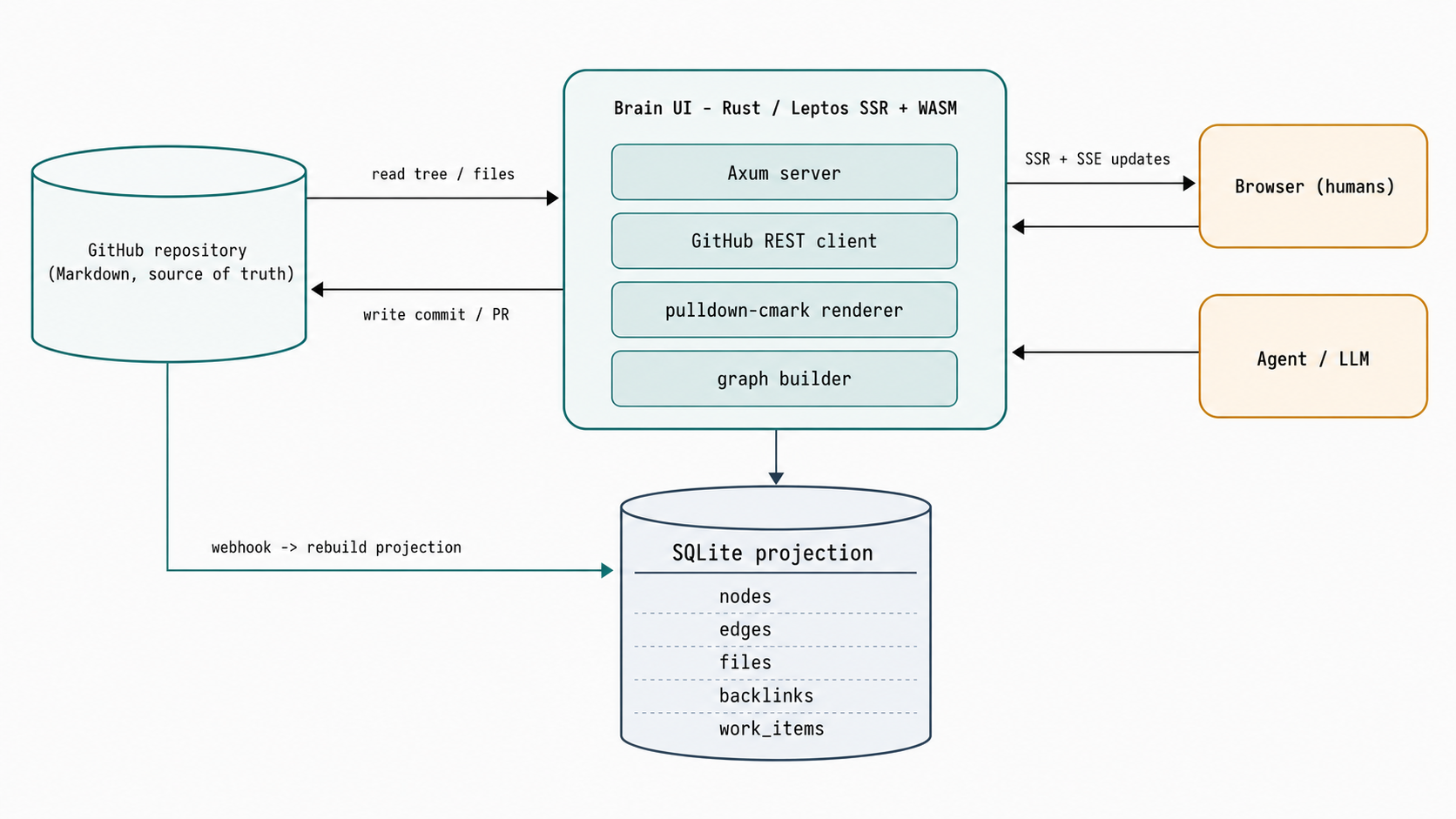
La separazione tra source of truth e proiezione è ciò che mantiene onesto tutto l’impianto.
Git e il repository target sono la source of truth. SQLite gli sta accanto e contiene tutto ciò che non è contenuto: sessioni, audit log, un registry dei target, un outbox di provider-sync, e una proiezione locale del grafo, scoped per target. Quella proiezione materializza le tabelle da cui Brain UI legge davvero a velocità: nodes, edges, files, backlinks, work_items e work_item_bindings. La proiezione è ricostruibile da Git in qualsiasi momento, con watermark espliciti e stato di errore, così non può mai derivare verso l’essere una seconda source of truth. Se è sbagliata, la butti via e la ricostruisci dai commit.
Alcuni pezzi tengono insieme il tutto:
- Routing multi-tenant tramite un
TargetRefcanonico. Brain UI non è legato a un solo repository. Il grafo, le sessioni SQLite e i canali di eventi per-target sono tutti chiavati per target, così un singolo deploy può servire molti Brain con isolamento dei permessi tra loro. - Scritture permission-aware. L’autenticazione è OAuth GitHub, e l’autorizzazione segue i permessi reali del repository. Un utente con
pullpuò leggere, uno conpushpuò scrivere direttamente, e dove la scrittura diretta non è consentita la modifica viene proposta come pull request. Brain UI non inventa un proprio modello di permessi, si affida a quello di GitHub. - Webhook e SSE. I push in entrata riconciliano la proiezione tramite un webhook, e un bus Server-Sent Events per-target spinge gli aggiornamenti ai client aperti. Quando il server non ha credenziali per riconciliare, la modifica viene segnalata come stale e ripresa al refresh successivo, senza mai bloccare.
Lo stack è volutamente noioso dove può esserlo e Rust dove conta: reqwest per il client REST di GitHub, pulldown-cmark per il rendering Markdown condiviso tra server e client, Tailwind per lo stile. Niente octocrab, nessun framework pesante che nasconde i pezzi in movimento.
La configurazione è dato, non codice
La feature di cui vado più fiero è che nessuno dei tipi di nodo è hardcoded nel binario. Cosa sia un “concept”, una “decisione” o una “fattura”, in quale cartella vive, che colore prende nel grafo, quali campi del frontmatter inizializza, e come si collega alle altre note, tutto questo è dichiarato in .brain-config.yml alla radice del repository target. Il binario porta un default sensato così un repo senza il file funziona comunque, ma oltre quello, la tassonomia è tua.
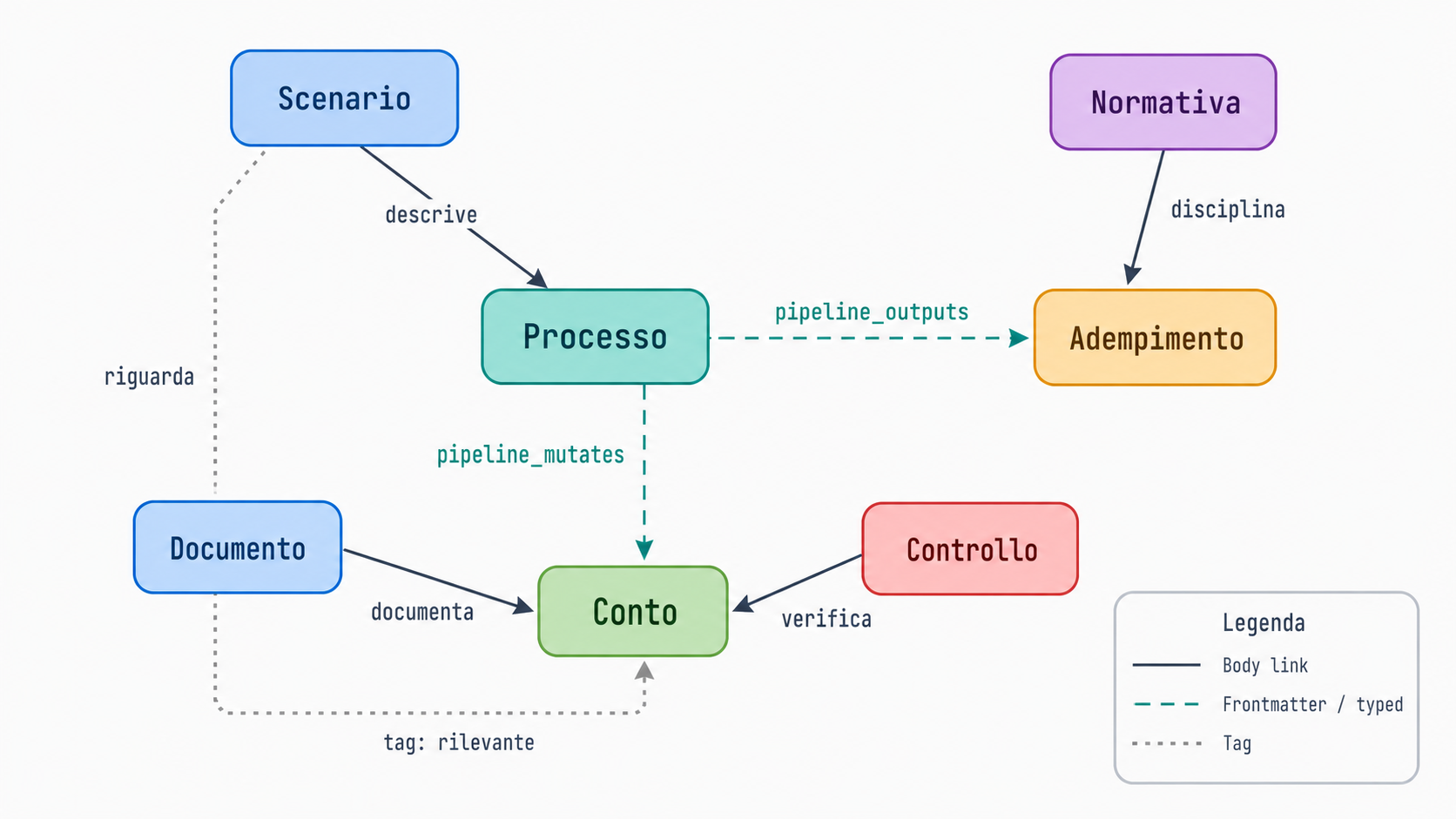
È questo che permette allo stesso binario Brain UI di servire un team software, una fan wiki di Pokémon e uno studio di commercialisti senza cambiare una sola riga di codice. Per renderlo concreto, ecco una fetta di una tassonomia che sto studiando: una knowledge base contabile e fiscale per il contesto italiano ed europeo.
| |
La tassonomia completa ha otto tipi di nodo reali (scenario, processo, adempimento, normativa, documento, controllo, conto, più un tipo tag sintetico) e un insieme di saved view che affettano lo stesso grafo lungo esigenze operative reali: IVA italiana e fatturazione elettronica, B2B cross-border, chiusura mensile, piano dei conti, paghe e ritenute.
La parte interessante è link_fields. Ogni voce mappa un campo del frontmatter a un tipo di nodo target. Così una nota processo che elenca pipeline_mutates_conti: [cash, vat-payable] nel suo frontmatter materializza archi tipizzati verso quelle note conto, etichettati con il nome del campo da cui provengono. Il graph builder risolve i valori slug contro i file esistenti e disegna gli archi, mentre gli slug che ancora non risolvono vengono ignorati silenziosamente, che è esattamente ciò che vuoi quando stai documentando qualcosa che sulla carta ancora non esiste.
Il canvas poi stila gli archi per tipo. Un arco Body è una citazione narrativa nel testo. Un arco Frontmatter(field) è strutturale, come una proprietà o uno step di pipeline. Un arco Tag è appartenenza debole. Una legenda ti permette di isolare un tipo dagli altri, così puoi guardare solo il flusso documento-conto, o solo i riferimenti normativi, senza che i link narrativi li sommergano. Il mock Pokémon che ho mostrato spinge forte su questo: un centinaio di nodi e un paio di centinaia di relazioni tipizzate, motivo per cui fa così bella figura su un proiettore.
Dritara, i tester che l’hanno reso reale
Qui devo essere preciso, perché conta. Dritara è un’azienda, ma di una persona sola, gestita da un mio amico. Non ne faccio parte legalmente. Ci collaboro su alcuni progetti. Brain UI è mio, ma Dritara è stato il primo tester di Brain e ha aiutato a portarlo in produzione da giorno zero.
Non è una nota a piè di pagina da poco. Dritara, l’amico che la gestisce e il suo stagista, sono diventati i primi utenti reali di Brain UI. Hanno dato feedback di continuo, spesso senza mai toccare il codice, semplicemente usando la cosa e dicendomi dove faceva male. Onestamente, penso che quei primi utenti siano uno dei motivi per cui la demo del 3 è andata così bene. Uno strumento usato sul serio, in produzione, da persone che non ne sono l’autore, si comporta in modo molto diverso da un side project che ha girato solo sul laptop dello sviluppatore. Gli spigoli vivi erano già stati limati da qualcuno che aveva bisogno che funzionasse.
Open source del core il 1 luglio
Il 1 luglio 2026 rilascio il core di Brain UI come repository pubblico pulito.
Il motivo è semplice: adozione, e sopravvivenza. È scritto in Rust, e faccio davvero fatica ad attrarre contributori o anche solo occhi interessati, la stessa difficoltà che ho avuto sugli altri miei progetti. Non voglio che Brain muoia in silenzio perché è vissuto in privato. Mettere il core in chiaro è la sua migliore possibilità di sopravvivere alla mia soglia di attenzione.
La forma del rilascio è stata pensata prima della data. Il piano è un repository core pubblico più un mirror privato downstream per Dritara, tenuti in sync con un semplice git remote e merge, così una patch di sicurezza a monte raggiunge la produzione con un singolo merge e nessun segreto o dato operativo vive mai nel repo pubblico. La separazione multi-tenant del lavoro su TargetRef aveva già disaccoppiato il grafo, le sessioni SQLite e i canali SSE da qualsiasi singolo repository d’ambiente, quindi lo sbrogliamento logico era in gran parte già fatto. Restava la bonifica: rendere la config un blueprint generico invece di una mappa operativa, ripulire i riferimenti interni, e scegliere una licenza, cosa che sto finalizzando ora.
Un abilitatore è arrivato giusto in tempo. Dal 6 giugno, Brain UI funziona in modalità org-less. Uno strumento open source che richiede una organizzazione GitHub è difficile da far adottare, perché la prima cosa che fa chi lo valuta è puntarlo su un repository personale. Il login gate ora separa la policy di login dalla proprietà del target, e l’autorizzazione reale passava già ovunque dai permessi live del repository, così un utente senza org può fare login e usare un repo personale secondo ciò che GitHub dice che può fare. Il minimo per farlo girare sono le credenziali OAuth e un TARGET_GITHUB_REPOSITORY=owner/repo.
Quello che non fingo
Preferisco dirlo chiaramente piuttosto che lasciarlo scoprire a qualcuno.
Temo che Brain UI non sia user-friendly quanto vorrei. E temo che le integrazioni AI reali oggi siano minime, anche se le fondamenta sotto sono solide. La proiezione ha content-hash per il rilevamento del drift, il layer di ricerca è pensato per essere esposto come tool, il grafo è tipizzato e interrogabile, il file di schema è esattamente il tipo di superficie di convenzioni che un agente vuole. Tutta la struttura di cui una llm-wiki ha bisogno c’è. La superficie agent-facing che trasforma quella struttura in qualcosa che un assistente mantiene attivamente è ancora sottile. C’è un’ironia che ti devo qui: Brain UI è stato costruito con un uso intensivo e quotidiano dell’AI come strumento di ingegneria, il workflow che ho descritto in 1 Anno di Claude Code, eppure la cosa che gli riesce peggio finora è proprio essere un buono strumento per gli agenti. Ho costruito prima il substrato, di proposito, ma il substrato non è la promessa. È la sua precondizione.
Quel divario è la ragione onesta per aprire il codice ora invece che dopo averlo rifinito. La rifinitura che mi manca è esattamente quella che arriva da più mani e più uso reale, non da altri mesi solitari.
Torniamo al signore con la foto
Ha fotografato un link che ancora non può usare. Il 1 luglio questo cambia, almeno per il core. La cosa interessante non è che l’URL diventa cliccabile. È che la domanda che la sala stava davvero facendo, come si costruisce una knowledge base aziendale che umani e agenti possano entrambi usare davvero, smette di essere una slide e diventa un repository che chiunque può clonare, forkare, puntare sul proprio Markdown, e rompere in modi a cui non ho ancora pensato.
Se vuoi seguire la cosa, il core pubblico arriva a luglio. Posterò il link quando sarà reale.
Un grazie a Matteo e Dritara, che hanno messo Brain UI al lavoro da giorno zero, l’hanno portato in produzione e gli hanno dato i suoi primi utenti reali. Uno strumento si guadagna i suoi spigoli vivi solo venendo usato da qualcuno che non ne è l’autore, e Brain UI si è guadagnato i primi proprio con lui. L’open source funziona quando c’è apertura, e qui l’ho trovata.