Introduction
Continuing the journey into the Rust data engineering ecosystem I started with the RisingWave article, I want to explore a project I recently contributed to: Lakekeeper, the REST catalog for Apache Iceberg entirely written in Rust.
I discovered Lakekeeper while searching for solutions to build a fully Rust-native lakehouse. After studying the codebase and contributing to the project, I realized it represents a fundamental piece to complete the vision of a modern, secure, and performant lakehouse.
From the Previous Article: The Missing Piece
In the RisingWave article, we saw how the Rust implementation of Apache Iceberg was born from a collaboration between RisingWave and Xuanwo, with the donation of the icelake project to the Apache Foundation. We discussed the gaps in the Rust-Iceberg ecosystem and how RisingWave was filling them to build modern streaming lakehouses.
But there was a crucial component still missing: the catalog. Without a secure, performant, and open catalog, the entire vision of a Rust-native lakehouse remained incomplete. Lakekeeper was born precisely to fill this gap.
The Problem Lakekeeper Solves
Existing catalogs have significant limitations. Unity Catalog, initially developed for Delta Lake in Databricks, is opening to the community but remains focused on the Databricks ecosystem. Apache Polaris, contributed by Snowflake, is vendor-neutral but requires a JVM. Both, while being valid solutions, don’t offer the combination of openness, customizability, on-premise support, and small footprint that many organizations seek.
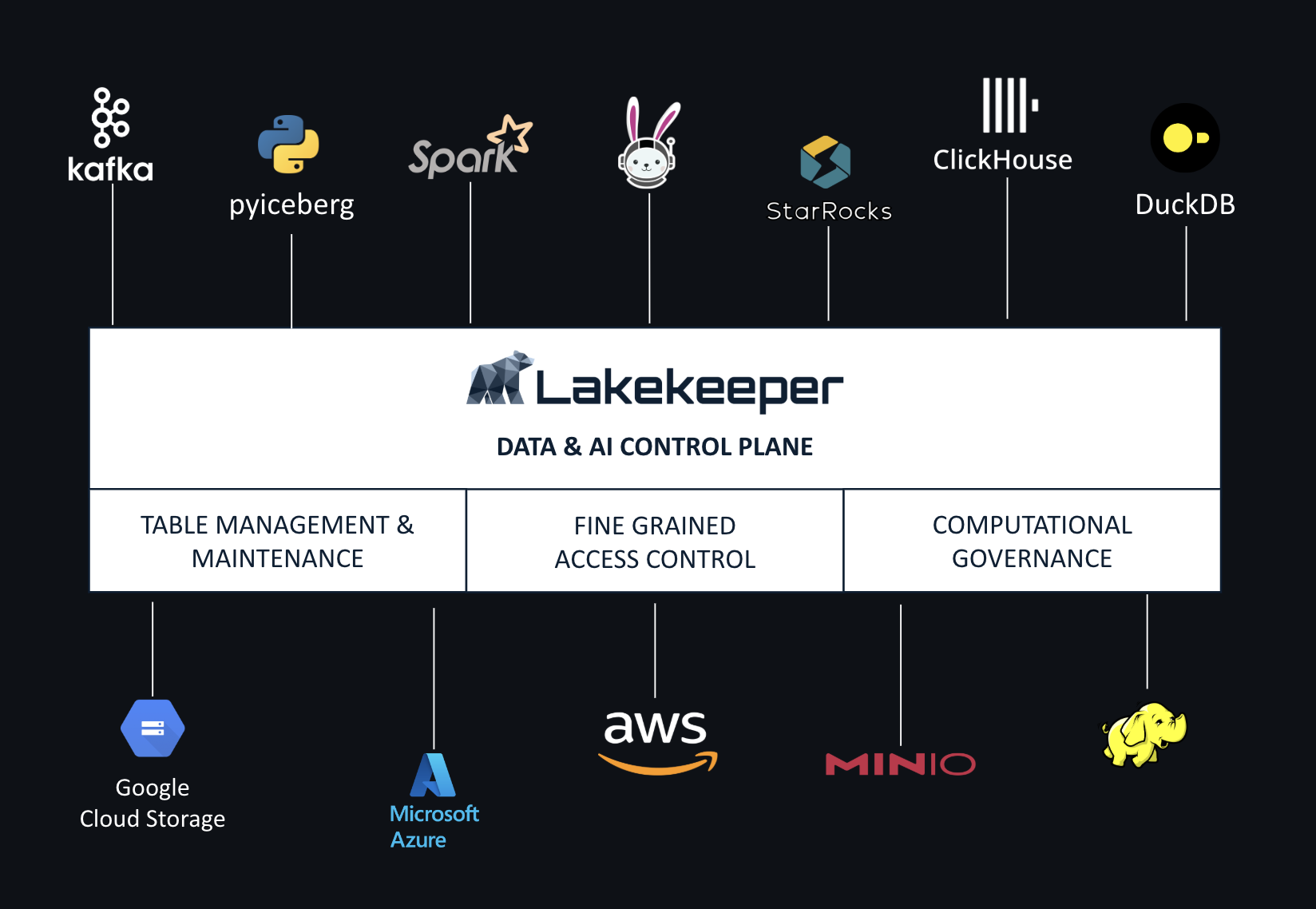
The catalog is essentially the “librarian” of the data lakehouse: it tracks which tables exist, where they are located, and which version of metadata is current. Without a catalog, storage systems like S3 remain simply a collection of files without governance. The catalog transforms ordinary storage into a fully governed lakehouse, supporting ACID transactions, time travel, and consistent views across all query engines.
Why Rust? Concrete Architectural Advantages
Lakekeeper is implemented entirely in Rust, a choice that brings measurable advantages:
Simplified deployment: Single binary of 30-70 MB without dependencies on JVM or Python runtime. Deployable even in distroless containers without shell, drastically reducing the attack surface and memory requirements.
High performance: Thanks to Rust’s ownership model and absence of garbage collection, Lakekeeper achieves low latencies for metadata operations and credential management. This translates to faster queries and lower operational costs.
Memory safety: Rust compiler guarantees eliminate entire classes of bugs (use-after-free, data races) that plague systems written in C/C++ or require manual attention in Go.
Customizability: The modular architecture exposes Rust traits for key components: Catalog, SecretsStore, Authorizer, CloudEventBackend, ContractVerification. In practice, you can integrate Lakekeeper into any enterprise stack by implementing a few interfaces.
Architecture and Main Components
Lakekeeper is structured around three main crates: iceberg-catalog contains the core logic, iceberg-catalog-bin provides the application entry point, while iceberg-ext extends the functionality of iceberg-rust. This modular structure reflects the Rust design pattern of reusable and easily testable components.
The system follows a stateless approach at the application level. State is persisted in a PostgreSQL database version 15 or higher, allowing horizontal scalability simply by adding instances.
For production deployments, Lakekeeper supports separate connections for reads and writes. This allows distributing read queries to dedicated PostgreSQL replicas, improving overall performance without modifying the application.
Two in-memory caches accelerate critical operations. The STC Cache stores temporary cloud credentials with a default limit of 10,000 entries. The Warehouse Cache reduces database queries for warehouse lookup, with a default of 1,000 entries. Both expose Prometheus metrics for granular monitoring: cache size, total hits, and total misses.
Security: Vended Credentials and Authorization
What struck me most about Lakekeeper is the Storage Access Management through vended credentials and remote signing. Instead of storing long-term credentials in clients, the catalog issues temporary credentials with scope limited to specific tables. In practice, this means implementing the principle of least-privilege access just-in-time, aligning with modern zero-trust security principles.
The process works like this: when a query engine needs to access a table, it authenticates with Lakekeeper using service credentials. The catalog verifies that the principal is authorized for that table and returns metadata along with temporary credentials for the storage location. These can be AWS STS tokens, Azure SAS tokens, or GCP OAuth 2.0.
Credentials have short expiration and minimal permissions, guaranteeing access only to files of that specific table. No more hardcoded credentials with permanent access to entire S3 buckets.
For authentication, Lakekeeper integrates natively with Identity Providers via OpenID Connect and supports Kubernetes Service Accounts. Configuration is simple: just specify the OpenID provider URI and the catalog automatically verifies access tokens.
For authorization, the system uses OpenFGA, a CNCF project that implements a permission model with bi-directional inheritance. This manages modern lakehouses with hierarchical namespaces, supporting granular grants at server, project, warehouse, namespace, table, and view levels.
Version 0.6.0 introduced the OPA bridge that exposes permissions managed by Lakekeeper to external query engines like Trino. Compute engines can thus automatically apply access policies at table, column, and row level without duplicating authorization logic.
Change Events and Event-Driven Governance
Lakekeeper natively supports Change Events based on CloudEvents, the CNCF standard for describing events uniformly. The catalog receives information about any table changes through REST endpoints called by clients. Lakekeeper transforms these table updates into CloudEvents, enabling real-time reaction to modifications.
Events can be emitted to configurable backends like NATS or Kafka. This enables interesting patterns: automatic triggering of data quality pipelines when new data is inserted, downstream cache invalidation when metadata changes, complete tracking of modifications for compliance, or integration with approval systems for change management.
The system also supports Change Approval via the ContractVerification trait. Modifications can be blocked by external systems, allowing for example to prevent changes that would violate Data Contracts or externally defined quality SLOs.
Multi-Tenancy and Production Deployment
Lakekeeper follows a multi-tenant approach: a single deployment can serve multiple projects, each with multiple warehouses to which compute engines can connect. All tenants share the same infrastructure but data is logically partitioned through identifiers.
Each project supports multiple warehouses, allowing segregation of environments like production, staging, and development, or different teams while maintaining a single centralized management point. The normalized database model introduced in version 0.5 stores TableMetadata through multiple tables instead of a single binary blob, making updates faster.
For production deployment, the checklist includes high-availability Postgres database, configuration of separate connections for read/write, deployment of multiple instances via official Helm chart, authentication via OpenID Connect, and configuration of Prometheus metrics with alerts for cache hit rate, latencies, and errors.
Integration with RisingWave: Complete Rust-Native Stack
The connection with RisingWave, discussed in the previous article, is particularly relevant. RisingWave introduced support for Iceberg REST catalogs in version 2.5, with native integration for Lakekeeper as the default catalog for self-hosted scenarios.
The practical example is simple: with docker-compose-with-lakekeeper.yml you start a RisingWave cluster and the Lakekeeper REST catalog. You create a connection in RisingWave pointing to Lakekeeper (catalog.type = 'rest', catalog.uri = 'http://lakekeeper:8181/catalog/'), set it as default, and any data streamed into the table is automatically committed in Iceberg format to object storage (MinIO, S3, Azure Blob).
On the query side, DuckDB, Spark, Trino, or Starburst can attach to the same Lakekeeper REST catalog and query tables created by RisingWave. This demonstrates multi-engine interoperability: RisingWave writes real-time data, Lakekeeper manages metadata and governance, other engines read data for batch analytics.
RisingWave has also integrated a compaction engine based on DataFusion, the Rust query execution framework that uses Apache Arrow as in-memory format. DataFusion is used as foundation for numerous projects (InfluxDB, ParadeDB, GreptimeDB, Arroyo) and is particularly suited for Iceberg compaction thanks to its performance and integration with the Arrow ecosystem.
This RisingWave + Lakekeeper + DataFusion stack represents a fully Rust-native architecture for streaming lakehouse: real-time ingestion, efficient compaction, secure catalog, all without JVM. It’s the paradigm shift from JVM-dominant architectures (Kafka → Spark → Data Warehouse) to polyglot Rust-accelerated architectures (RisingWave → Iceberg → Lakekeeper → Data Lakehouse).
Lakekeeper in the 2025 Catalog Landscape
In the landscape of Iceberg catalogs, Lakekeeper stands out for specific characteristics:
Apache Polaris (incubating), developed by Snowflake and contributed to Apache, is a fully-featured vendor-neutral catalog that implements the standard Iceberg REST API. Polaris can be run as a centralized service or hosted in Snowflake cloud, supporting different engines.
Databricks Unity Catalog is a proprietary unified governance solution for data and AI assets in the Databricks lakehouse. While Unity supports Iceberg, it’s optimized primarily for Delta Lake.
Lakekeeper positions itself as an alternative with:
- Lightweight footprint: Single binary 30-70MB vs JVM-based solutions
- Built-in security: Vended credentials, OpenFGA, native OIDC integration
- Complete openness: Apache License without vendor lock-in
- On-premise and hybrid focus: Beyond cloud, robust support for self-hosted deployments
Adoption and Ecosystem
Lakekeeper is already used in various contexts. It appears in the “Users” list of the apache/iceberg-rust repository alongside Databend, RisingWave, and Wrappers. It’s integrated by managed platforms like Starburst, ClickHouse, and Crunchy Data Warehouse.
The project released version 0.1.0-rc1 in June 2024 and has followed a monthly cadence since. Version 0.6.0 introduced the OPA bridge for Trino and support for Iceberg 1.5-1.7. Version 0.7.0 added Azure Managed Identities and CloudEvents for undropTabulars. Version 0.8.1 introduced protections for tables, views, namespaces, and warehouses.
My Contribution to the Project
I started following Lakekeeper attracted by the promise of an Iceberg catalog written in Rust that solved openness and customizability problems. After studying the codebase, I identified an area where I could contribute and opened a pull request that was merged.
The contribution experience was positive: the review process is fast and constructive, all commits go through PRs with rigorous CI checks (lints, integration tests with Spark, PyIceberg, Trino, StarRocks). The project has extensive integration tests that guarantee multi-engine compatibility.
The project currently requires the CLA (Contributor License Agreement) signed on GitHub, but they’re planning to donate Lakekeeper to a foundation - probably Apache, Linux Foundation, or a dedicated Lakekeeper Foundation - during 2026.
Why Lakekeeper Needs Contributors
Lakekeeper is a promising project that would benefit enormously from more contributors. Some areas where the community can contribute:
Feature development: Support for HDFS as Storage Profile is not yet complete. The Views ecosystem in Iceberg is evolving and requires further integration tests.
Documentation: Although official documentation at docs.lakekeeper.io has improved significantly, there are always advanced use cases to document.
Integration testing: More coverage for different compute engines (Flink, Presto, others) would help stability.
Kubernetes Operator: Currently work-in-progress, it represents a priority to simplify enterprise deployments.
If you’re interested in the intersection between Rust and data engineering, Lakekeeper represents an excellent opportunity to contribute to a project with real impact on the open lakehouse ecosystem.
Roadmap and Future Vision
The future roadmap includes extensions of the catalog concept beyond Iceberg: managing AI objects, volumes metadata for model training on PDFs and images. The catalog can evolve to provide access control for AI assets via volume metadata, expanding lakehouse governance to the entire data-AI stack.
The Kubernetes Operator will simplify enterprise deployment by managing Lakekeeper as a Custom Resource. Integration with additional Identity Providers and authorization systems is under discussion to support different enterprise stacks.
Conclusion: Completing the Rust-Data Puzzle
Lakekeeper, in the context of the previous article on RisingWave, completes the picture of a credible Rust-native streaming lakehouse architecture. It’s not just an alternative Iceberg catalog: it’s an example of how governance, security, and performance can coexist in an open and customizable system.
The Rust ecosystem in data engineering is still young but rapidly growing. Rust’s integration into the Linux kernel (2024) and adoption by cloud providers (AWS Firecracker) signal growing acceptance in critical infrastructures. Lakekeeper positions itself in this transition: mature enough for production, agile enough to innovate rapidly.
For organizations building modern lakehouses, Lakekeeper offers a path toward full metadata ownership, freedom from vendor lock-in, and enterprise-grade governance while maintaining the openness of the open data ecosystem. The Rust choice is not just technical but strategic: it positions Lakekeeper at the heart of the evolution toward cloud-native, performant, and secure data stacks.
If you’re interested in contributing, the project is on GitHub with complete documentation, quick-start guides, and a clear roadmap. The ecosystem needs more people who believe in open standards and real collaboration on data.