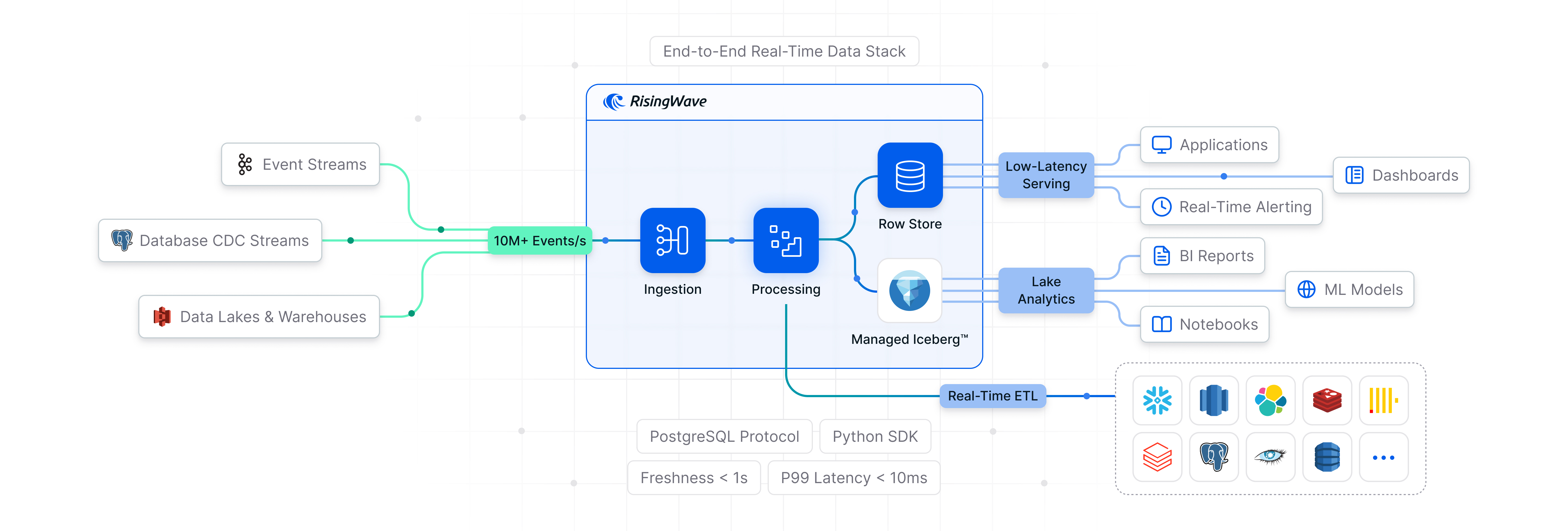
Introduction
The Apache Iceberg ecosystem is undergoing a fascinating transformation. While the Java community maintains a mature, established implementation, a parallel movement in Rust is gaining momentum, bringing opportunities to build truly efficient, scalable, and developer-friendly streaming data lakehouses. RisingWave, a streaming platform built entirely in Rust, is a main protagonist in this revolution, and its integration with Iceberg-Rust offers a compelling case study for how new implementations of the Iceberg format are changing modern data engineering.
The Origin: From icelake to Apache Iceberg Rust
The story begins well before the official launch of Apache Iceberg Rust as an Apache project. In 2024, a visionary developer named Xuanwo created icelake, an unofficial Rust library for interacting with Apache Iceberg. The project had potential but remained isolated.
Then, something important happened: RisingWave discovered icelake and saw its potential. The RisingWave team, led by founder and CEO Yingjun Wu, decided this was the missing piece of their puzzle. Instead of developing a competing Iceberg implementation in Rust, they decided to collaborate with the community.
Xuanwo and RisingWave contributors (including ZENOTME) integrated icelake, fixed bugs, added write support, and built a robust Iceberg sink. This collaboration perfectly embodies the open source philosophy: Community Over Code. The result? In 2024 the project was donated to the Apache Software Foundation, becoming Apache Iceberg Rust, the official project.
This was a turning point: two problems solved at once. RisingWave gained a robust, community-maintained Rust Iceberg library. The Rust community received a real-world production use case that would drive priorities, bug fixes, and the roadmap.
The Challenge RisingWave Addresses: Streaming CDC to Iceberg
It is important to understand the unique problem that RisingWave solves. When you want to stream from transactional databases (PostgreSQL, MySQL, SQL Server) to Iceberg in real-time via CDC (Change Data Capture), you face a hard challenge: how to manage row-level deletes?
Apache Iceberg offers two mechanisms:
Position Delete: Deletes by physical location (file path + row number). Extremely fast for queries, but requires knowing the row’s physical location. For streaming CDC, this means querying Iceberg for each delete, resulting in random I/O and unacceptable latency.
Equality Delete: Deletes by column value (typically primary key). More natural for CDC because you don’t need the row’s file location, only its key value. However, this creates numerous delete files, which can amplify query read cost.
Most pipelines picked one approach and accepted the tradeoffs. With iceberg-rust, RisingWave chose a novel path.
The Solution: RisingWave and Iceberg-Rust in Synergy
1. Hybrid Delete Strategy
RisingWave implements a smart strategy:
- Primary keys updated multiple times in the same batch: Use Position Delete (efficient because the location is already known within the batch)
- Updates/deletes outside the current batch: Use Equality Delete (a pragmatic CDC streaming choice)
This is possible thanks to the deep integration between RisingWave and iceberg-rust, with code-level cooperation that is well beyond what a generic HTTP client could achieve.
2. Schedulable Compaction
Enter another crucial Rust component: DataFusion. RisingWave leverages Apache DataFusion for intelligent compaction that:
- Periodically removes equality delete files
- Compacts small files into larger ones
- Reduces read amplification without sacrificing data freshness
Multiple compaction modes are supported depending on the workload:
- Low-latency mode: frequent compaction for fast real-time queries
- Partial compaction: limits scope based on key ranges
- Large-scale optimization: multi-node parallel compaction for TB/PB-scale tables
3. Export Phase: Cross-Engine Compatibility
RisingWave knows that not all query engines support equality delete (Databricks, external Snowflake, Redshift have limitations). So, it executes targeted compaction before export to generate a “clean” version without delete files:
- Internal real-time queries continue to use the version with equality delete (low latency)
- External query engines receive a clean, compatible version
4. Exactly-Once Delivery via Two-Phase Commit
Unlike Flink CDC or Kafka Connect solutions, RisingWave uses a custom logstore with idempotent commits:
- All commits are reproducible and verifiable
- Zero duplicates, zero data loss
- Minimal overhead, ideal for high-frequency update/delete scenarios
This is enabled by the tight integration with iceberg-rust, giving RisingWave direct control over the Iceberg commit lifecycle.
The Full Rust Stack: When Everything Comes Together
RisingWave does not use iceberg-rust in isolation. It’s just one part of a broader Rust ecosystem:
- RisingWave: 100% Rust-built streaming database with S3 as primary storage
- Apache Iceberg Rust: Native Iceberg library
- Apache DataFusion: Distributed query engine, used by RisingWave for compaction
- Apache OpenDAL: Unified storage abstraction that RisingWave uses (supports S3, GCS, Azure Blob)
- Apache Arrow: In-memory data format for Rust and polyglot languages
This stack represents a fundamental shift in data platform architecture. It’s not JVM + Scala/Java. It’s not Python + Spark. It’s Rust end-to-end, with the performance, memory safety, and absence of garbage collection delays that brings.
Real-World Case Study: Siemens
Siemens, an enterprise customer, previously had a pipeline like this:
Countless moving parts, countless configuration points, countless failure points. With RisingWave and iceberg-rust, the pipeline became:
Benefits:
- Latency: From hours (batch Spark) to seconds (continuous streaming)
- Operations: No Debezium or Kafka to configure, monitor, or upgrade
- Cost: 90% cheaper than frequent Spark jobs
- Reliability: Exactly-once semantics guaranteed natively
Siemens implements RisingWave’s hybrid delete strategy:
- Position delete for primary keys updated multiple times per batch
- Equality delete for out-of-batch updates/deletes
- Automatic scheduled compaction that removes equality delete files at the right time
The result? Siemens’ risk control systems get real-time visibility into Iceberg data with second-level latency, while Snowflake receives a clean, compatible version of the data for analytics.
The Gaps in Iceberg-Rust That RisingWave Is Helping Close
Recall from earlier research that Iceberg-Rust has several gaps compared to the Java version. RisingWave is demonstrating how to overcome them in practice:
- Write Operations: RisingWave continuously contributes improvements to iceberg-rust for write performance and support for new operations
- Delete Handling: RisingWave’s hybrid solution has become a model for how other libraries should approach the problem
- Compaction: RisingWave contributes improvements to DataFusion for Iceberg compaction
- Transactions: The two-phase commit primitives RisingWave uses influence the design of future transactions in iceberg-rust
RisingWave is not just a user of iceberg-rust; it’s a driver of Rust ecosystem innovation.
The Broader Implication: A New Data Engineering Paradigm
The synergy between RisingWave and Iceberg-Rust represents something deeper than a simple product integration. It represents the emergence of a new paradigm:
Before (JVM-dominant):
Now (Polyglot, Rust-accelerated):
Benefits:
- Performance: Rust delivers top-tier performance without garbage collection pauses
- Memory efficiency: Streaming CDC with RisingWave uses a fraction of the memory equivalent Spark jobs require
- Latency: Sub-100ms query latency for streaming analytics
- Cost: AWS reports 90% cost reduction vs. Spark-based approaches
- Flexibility: Interoperability with Databricks, Snowflake, Redshift via the Iceberg standard
Challenges and Considerations
Despite the progress, challenges remain:
- Maturity: Iceberg-Rust is still at v0.7.0. Not all edge cases are covered compared to Java.
- Puffin & Deletion Vectors V3: Still under development. RisingWave supports V2 for now.
- Cross-engine testing: RisingWave uses Spark tests through DataFusion Comet, but not all combinations have been tested.
- Community size: The contributor team is smaller than Java, which means less bandwidth for bug fixes.
But these are “works in progress,” not fundamental blockers.
Conclusion: The Future Is Streaming + Lakehouse + Rust
The partnership between RisingWave and Iceberg-Rust is not an anomaly; it’s a window into where modern data engineering is headed.
RisingWave chose to build on the foundation of iceberg-rust instead of reinventing. In return, it gained a robust library that is actively maintained and continuously improved by the community. The Rust ecosystem gained a production use case that drives innovation and priorities.
For organizations looking ahead, the message is clear: the data platform landscape is no longer JVM-dominated. Rust is not an eccentric niche choice; it’s a pragmatic alternative with performance, memory safety, and operational efficiency that make it attractive for modern streaming data lakehouses.
If you’re building real-time data pipelines, considering Iceberg for open data lakes, or interested in the future of data platforms, RisingWave + Iceberg-Rust is a case study that deserves your attention.
Recommended Resources
- RisingWave documentation: Interact with Apache Iceberg
- Apache Iceberg Rust: https://github.com/apache/iceberg-rust
- The Equality Delete Problem in Apache Iceberg (RisingWave blog)
- Postgres CDC to Iceberg: Lessons from Real-World Data Engineering (RisingWave blog)
- Deep Dive: S3-as-primary-storage Architecture (RisingWave blog)