
A man took a photo of the link
On June 3rd I was at Talent Garden in Rende, on stage, with the talk also streamed on StreamYard thanks to the friends at Azure Meetup Puglia who ran it. Around fifty or sixty people in the room. I demoed Brain UI live on a Pokémon mock dataset, the most visually loud taxonomy I have, the one where the graph really comes alive.
At some point my girlfriend, watching from the seats, noticed a man in the audience taking a photo of the domain shown on screen. He will be a little disappointed: he cannot use it that way yet. That small moment made me smile, and it stuck with me, because it captured the thing the whole room seemed to share that evening. Not curiosity about a Pokémon graph, but a real common interest in one question: what does a company knowledge base actually look like when you want it to be usable by both humans and agents, not just one or the other.
This post is the deep dive I did not have time for on stage. What Brain and Brain UI are, how the two halves connect, a real config-driven taxonomy from a domain I have been studying, and the honest reasons I am about to open-source the core.
Two halves: Brain and Brain UI
The system is deliberately split in two.
Brain is the content. It is a plain folder of Markdown files versioned in Git. Atomic notes, decisions, meeting captures, runbooks, work items, estimates. No database holds the truth, no proprietary format locks it in. If Brain UI disappeared tomorrow, Brain would still be a clean Git repository of Markdown you can read in any editor, grep from a terminal, or hand to any other tool. That is the point.
Brain UI is the control plane. It is a Rust application built on Leptos 0.8, server-side rendered with WASM hydration, with Axum 0.8 underneath for the HTTP server, sessions, and auth. It reads the Markdown from a GitHub repository, renders it, lets you edit and create documents that get written back through the GitHub API, and visualizes the relationships between notes as an interactive graph.
The connection between the two is the part I care about most: Git stays the single source of truth, always. Brain UI never becomes the place where your knowledge secretly lives. Every write goes back to GitHub as a real commit, with a real diff, that you could have made by hand. Brain UI is a lens and an editor over your repository, not a silo that owns your data.
Why I built it
The honest origin is unglamorous: documentation that was scattered and fragmented across too many places. Brain is the attempt to pull it into one common point, easy to export, with full ownership of the data. Plain text in Git means there is no vendor between me and my own knowledge.
While I was building it, Andrej Karpathy published his llm-wiki gist, and it described, almost line for line, the shape I was already converging on. A personal knowledge base made of plain Markdown that an agent actively builds and maintains: raw sources stay immutable, a wiki layer is owned by the LLM, and a schema file (he names CLAUDE.md or AGENTS.md) holds the conventions. Three operations: ingest, query, lint. Lint in particular looks for contradictions and for orphan pages with no links pointing in.
Brain landed in the same territory from the other direction. The schema file exists, it is called .brain-config.yml. Brain itself carries an AGENTS.md. Brain UI already surfaces orphan nodes with an advisory banner and resolves cross-references as graph edges. The difference is that I wanted a real interface on top of the folder, something a non-engineer can open and navigate, not only a coding agent pointed at a directory. A knowledge base that is genuinely usable for humans and agents at the same time was the goal from the start.
The architecture
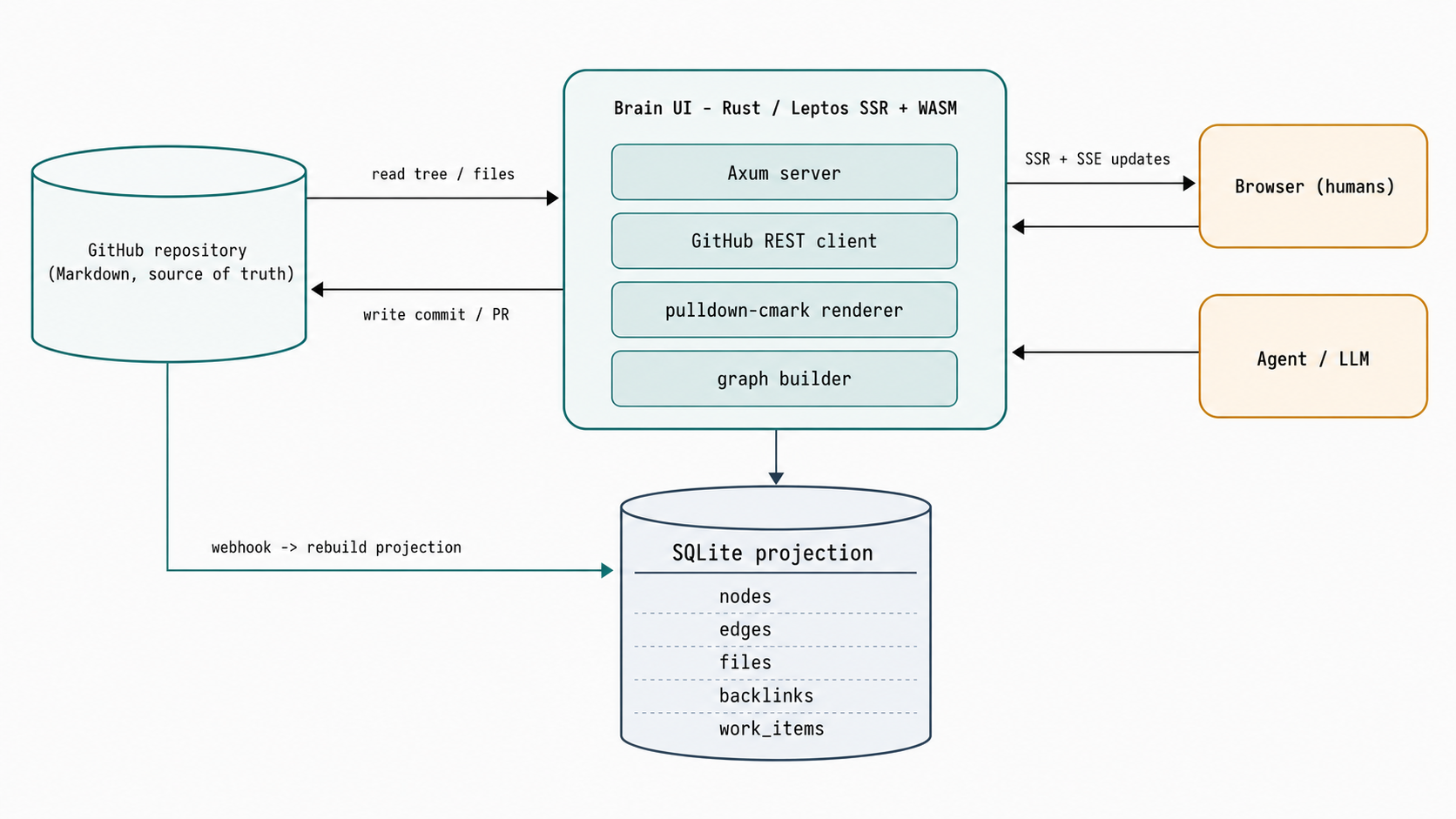
The split between source of truth and projection is what keeps the whole thing honest.
Git and the target repository are the source of truth. SQLite sits beside it and holds everything that is not content: sessions, the audit log, a target registry, a provider-sync outbox, and a target-scoped local projection of the graph. That projection materializes the tables Brain UI actually reads from at speed: nodes, edges, files, backlinks, work_items, and work_item_bindings. The projection is rebuildable from Git at any time, with explicit watermarks and error state, so it can never drift into being a second source of truth. If it is ever wrong, you throw it away and rebuild it from the commits.
A few pieces hold it together:
- Multi-tenant routing via a canonical
TargetRef. Brain UI is not bound to one repository. The graph, the SQLite sessions, and the per-target event channels are all keyed by target, so one deployment can serve many Brains with permission isolation between them. - Permission-aware writes. Authentication is GitHub OAuth, and authorization follows live repository permissions. A user with
pullcan read, a user withpushcan write directly, and where direct write is not allowed the change is proposed as a pull request instead. Brain UI does not invent its own permission model, it defers to GitHub’s. - Webhooks and SSE. Inbound pushes reconcile the projection through a webhook, and a per-target Server-Sent Events bus pushes updates to open clients. When the server has no credential to reconcile, the change is signalled as stale and picked up on the next refresh, never blocking.
The stack is intentionally boring where it can be and Rust where it matters: reqwest for the GitHub REST client, pulldown-cmark for Markdown rendering shared between server and client, Tailwind for styling. No octocrab, no heavy framework hiding the moving parts.
Configuration is data, not code
The feature I am proudest of is that none of the node types are hardcoded in the binary. What a “concept” or a “decision” or an “invoice” is, which folder it lives in, what colour it gets in the graph, which frontmatter fields it seeds, and how it links to other notes, all of that is declared in .brain-config.yml at the root of the target repository. The binary ships a sensible default so a repo without the file still works, but past that, the taxonomy is yours.
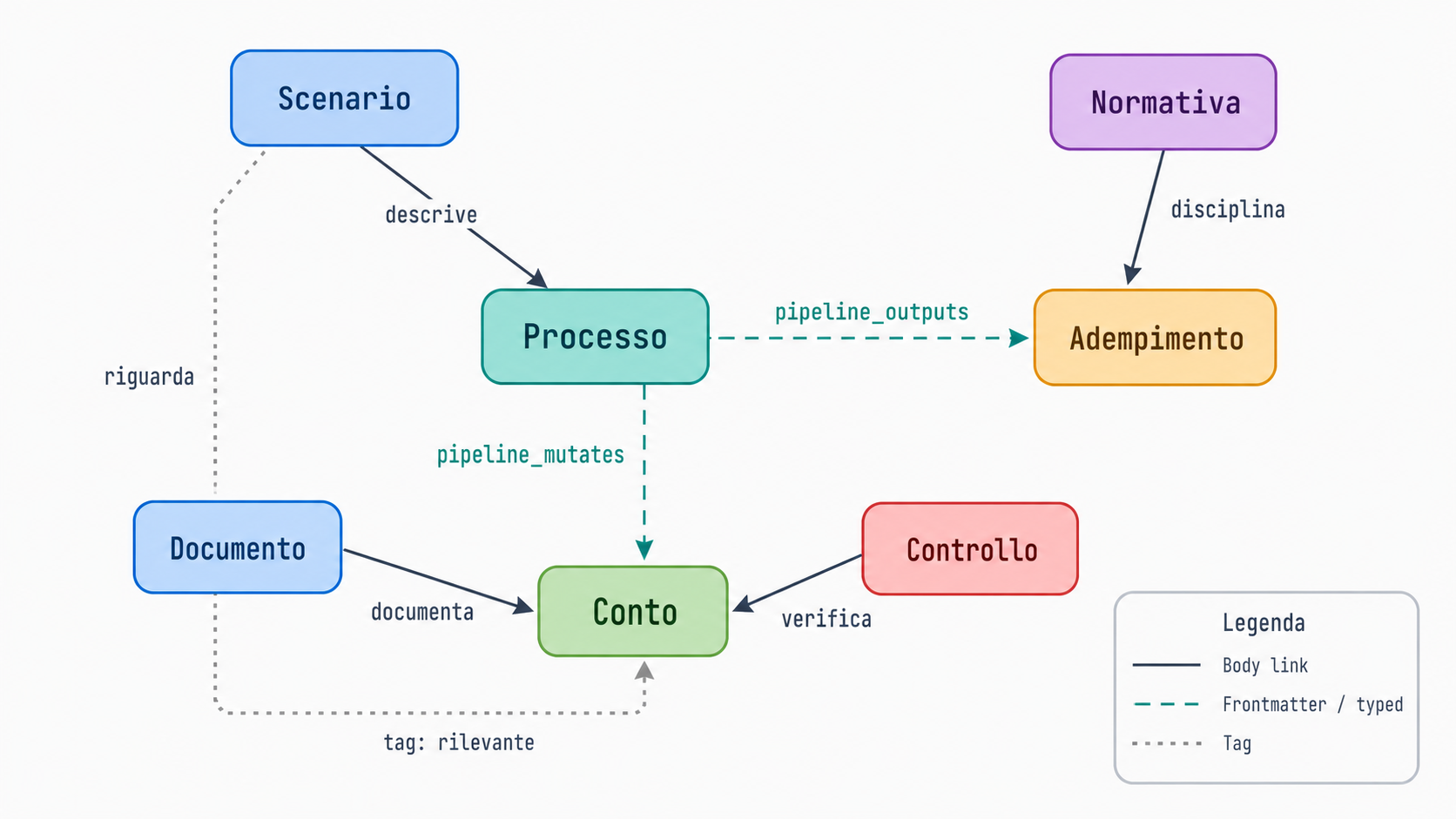
This is what lets the same Brain UI binary serve a software team, a Pokémon fan wiki, and an accounting practice without a single line of code changing. To make that concrete, here is a slice of a taxonomy I have been studying: an accounting and tax knowledge base for the Italian and EU context.
| |
The full taxonomy has eight real node types (scenario, process, obligation, regulation, document, control, account, plus a synthetic tag type) and a set of saved views that slice the same graph along real working concerns: Italian VAT and e-invoicing, cross-border B2B, monthly close, the chart of accounts, payroll and withholdings.
The interesting part is link_fields. Each entry maps a frontmatter field to a target node type. So a processo note that lists pipeline_mutates_conti: [cash, vat-payable] in its frontmatter materializes typed edges into those account notes, tagged with the field name they came from. The graph builder resolves the slug values against existing files and draws the edges, while slugs that do not resolve yet are silently ignored, which is exactly what you want when you are documenting something that does not exist on paper.
The canvas then styles edges by kind. A Body edge is a narrative citation in the prose. A Frontmatter(field) edge is structured, like ownership or a pipeline step. A Tag edge is weak membership. A legend lets you isolate one kind from the others, so you can look at just the document-to-account flow, or just the regulatory references, without the narrative links drowning them out. The Pokémon mock I demoed pushes this hard: roughly a hundred nodes and a couple hundred typed relationships, which is why it photographs so well on a projector.
Dritara, the testers who made it real
I have to be precise here, because it matters. Dritara is a company, but a one-person one, run by a friend of mine. I am not legally part of it. I collaborate with it on some projects. Brain UI is mine, but Dritara was Brain’s first tester and helped take it to production from day zero.
That is not a small footnote. Dritara, the friend who runs it and his intern, became the first real users of Brain UI. They gave feedback continuously, often without ever touching the code, just by using the thing and telling me where it hurt. Honestly, I think those early users are one of the reasons the demo on the 3rd went as well as it did. A tool that has been used in anger, in production, by people who are not its author, behaves very differently from a side project that only ever ran on the developer’s laptop. The rough edges had already been filed down by someone who needed it to work.
Open-sourcing the core on July 1st
On July 1st 2026 I am releasing the core of Brain UI as a clean public repository.
The reason is plain: adoption, and survival. It is written in Rust, and I am finding it genuinely hard to attract contributors or even interested eyes, the same difficulty I have had on my other projects. I do not want Brain to quietly die because it lived in private. Putting the core in the open is the best chance it has of outliving my own attention span.
The shape of the release was designed before the date. The plan is a public core repository plus a private downstream mirror for Dritara, kept in sync with a plain git remote and merges, so a security patch upstream reaches production with a single merge and no secrets or operational data ever live in the public repo. The multi-tenant separation from the TargetRef work already decoupled the graph, the SQLite sessions, and the SSE channels from any single environment repository, so the logical untangling was largely done already. What remained was cleanup: making the config a generic blueprint instead of an operational map, scrubbing internal references, and choosing a license, which I am finalizing now.
One enabler shipped exactly in time. As of June 6th, Brain UI runs in org-less mode. An open-source tool that requires a GitHub organization is a hard sell, because the first thing an evaluator does is point it at a personal repository. The login gate now separates login policy from target ownership, and the real authorization everywhere already flowed through live repository permissions, so a user with no org can log in and use a personal repo according to what GitHub says they can do. The minimum to run it is OAuth credentials and one TARGET_GITHUB_REPOSITORY=owner/repo.
What I am not pretending
I would rather say this plainly than have someone discover it.
I worry Brain UI is not as user-friendly as I want it to be. And I worry that the actual AI integrations today are minimal, even though the foundations under them are solid. The projection is content-hashed for drift detection, the search layer is built to be exposed as a tool, the graph is typed and queryable, the schema file is exactly the kind of convention surface an agent wants. All the structure an LLM wiki needs is there. The agent-facing surface that turns that structure into something an assistant actively maintains is still thin. There is an irony I owe you here: Brain UI was built with heavy day-to-day use of AI as an engineering tool, the workflow I described in One Year of Claude Code, and yet the thing it does least well so far is be a good tool for agents. I built the substrate first, on purpose, but the substrate is not the promise. It is the precondition for it.
That gap is the honest reason to open the code now rather than after it is polished. The polish I am missing is exactly the kind that comes from more hands and more real use, not from more solitary months.
Back to the man with the photo
He photographed a link he cannot use yet. On July 1st that changes, at least for the core. The interesting thing is not that the URL becomes clickable. It is that the question the room was really asking, how do you make a company knowledge base that humans and agents can both actually use, stops being a slide and becomes a repository anyone can clone, fork, point at their own Markdown, and break in ways I have not thought of yet.
If you want to follow along, the public core lands in July. I will post the link when it is real.
A thank you to Matteo and Dritara, who put Brain UI to work from day zero, carried it into production, and gave it its first real users. A tool only earns its rough edges by being used by someone other than its author, and Brain UI earned its early ones with him